
新作アプリ「Scaling」を公開しました。
拡大縮小率を計算するだけの単純なアプリです。
ダウンロードはScalingのページからどうぞ。
どこにでもありそうだけど、なぜかどこにもないので作りました。
新作アプリ「Scaling」を公開しました。
拡大縮小率を計算するだけの単純なアプリです。
ダウンロードはScalingのページからどうぞ。
どこにでもありそうだけど、なぜかどこにもないので作りました。
Illustratorファイルには「アプリバージョン」「互換バージョン」の2種類の情報が記録されています。v8以降で保存されたファイルなら、この2つが確実に記録されています。
ファイルをエディタ等で読み込み、特定の記録箇所を見つけることで、バージョン情報を確認できます。
実際にファイルを開いて保存したIllustratorアプリのバージョンです。
記録箇所は「%%AI8_CreatorVersion:」です。
例)
%%AI8_CreatorVersion: 8.0.1
%%AI8_CreatorVersion: 15.1.0
%%AI8_CreatorVersion: 26.5.3
フルバージョンがしっかりと記録されています。保存する毎に正確に記録されるので最も信頼性の高い情報です。ファイル内に1箇所だけ出現します。
Illustrator/EPSオプションの設定バージョンです。
記録箇所は「%%Creator: Adobe Illustrator(R)」です。
例)
%%Creator: Adobe Illustrator(R) 8.0
%%Creator: Adobe Illustrator(R) 15.0
%%Creator: Adobe Illustrator(R) 24.0
バージョンダウン保存されているかどうかを確認するところです。これも保存する毎に正確に記録されます。
aiファイルは、ファイル内に1箇所だけ出現します。
epsファイルは、ファイル内に2箇所出現します。1つめではなく、2つめが互換バージョン情報なので注意しましょう。
ファイル内には上記の他にもバージョン情報が散見されます。どれも不正確になりがちなので信用してはいけません。例えば、「<xmp:CreatorTool>」はBridgeの「メタデータ>ファイルプロパティ>アプリケーション」に表示される情報ですが、別名保存以外の保存操作では情報が更新されません。不正確になりがちなので信用してはいけません。
ローカル保存ではなくクラウド保存すると、「アプリバージョン」を確認する方法は全くありません。
クラウド保存したものをaiファイルでダウンロードしても、そのaiファイルは、その時点で運用されているAdobeのサーバにあるIllustratorアプリで保存されたものになってしまいます。もともと何のアプリバージョンだったのかを確認する手立てはありません。
File List Printを2.7.0にアップデートしました。
ダウンロードはFile List Printのページからどうぞ。
2.6.0で追加した新機能がさらに便利になりました。
Illustratorファイルのアプリバージョン判定も少し改善しました。数MB程度のファイルサイズなら若干速くなったかもしれません。それ以上になると(とくにEPSで)全部読み込んでやっと判定できるようになるので、やはりファイルサイズが大きいほど激遅です…。
File List Printを2.6.0にアップデートしました。
ダウンロードはFile List Printのページからどうぞ。
InDesignファイルとIllustratorファイルの作成アプリバージョンを表示する機能を追加しました。長年ずっと構想していたもので、ついに実現しました。
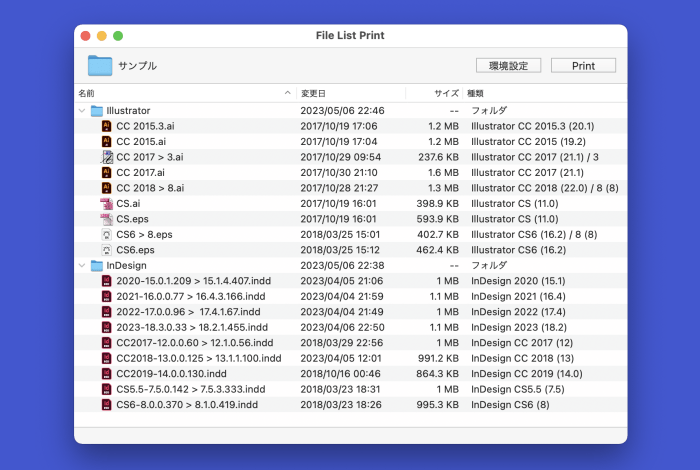
新機能ではあるものの、デフォルトではOFFになっています。新機能を使用するには、環境設定を変更する必要があります。そもそも、File List PrintはDTP用ではなく、一般的な使い方がされることを想定しています。デフォルトは一般的な状態にしておくのが最善と判断しました。さらに、ONにすると処理速度の低下が避けられないので、一般的な用途ではやはりデフォルトをOFFにするのが落とし所と考えました。

indd、ブック、ライブラリ、テンプレートの4種が対象です。ファイル先頭の数十バイトを読み込むだけで済むので、処理速度への影響は軽微です。設定をONにすれば確実にバージョンが表示されます。
ただし、InDesignは、ファイル内のバージョン情報を正確に記録できない状況が長く続いていました。メジャーバージョンは正確なのですが、マイナーバージョンを正確に記録するのは別名保存がされた時だけでした。この状況はCC 2018(13)まで続きます。そして、CC 2019(14)から、普通に保存するだけでマイナーバージョンが正確に記録されるように改善されました(たぶん本当は2020(15)からなのでしょうけど、CC 2019は14.1が存在せず14.0だけなので正確であるとしています)。
File List Printでのバージョン表示は、CC 2018(13)まではメジャーバージョンのみ、CC 2019(14)以降はマイナーバージョンを含めたものにしています。
ai、eps、テンプレートの3種が対象です。InDesignと異なり、バージョン情報は相当量のデータを読み込まないと出現せず、その出現位置も一定ではありません。だからといってファイルを全て読み込むと、重いファイルは処理速度が激遅になってしまうためストレスフルです。File List Printは複数ファイルを扱うので、処理速度への影響を極力抑えなければいけません。その落とし所として、読込制限データサイズを設けて、デフォルトでは10MBとしました。
10MBではバージョンを検出できないファイルが必ずあります。普段扱うIllustratorファイルがどのくらいの重さなのかは、人によってかなりばらつきがあるでしょう。読込制限サイズは各自の環境に合わせて調整してみてください。すべて検出するのを目指すのではなく、重いファイルはGlow Aiなどでバージョンを調べるなど、無理をしない方針で設定するのをお勧めします。
なお、拡張子がないファイル(Classic Mac OS時代の古いIllustratorファイル)は対象外です。これを対象に含めると処理速度への影響が無視できないものになるので対象外としました。
File List Printでのバージョン表示は、バージョンダウン保存していなければ作成アプリバージョンのみを表示します。バージョンダウン保存されているファイルには互換バージョンも含めて表示します。
DTP Zipperを1.3.0にアップデートしました。
ダウンロードは DTP Zipperのページからどうぞ。
起動時に表示していたアラートを廃止して、ドロップすると圧縮を実行できるウインドウを表示するようにしました(thanks あかつきさん)。
実はこの1.3.0、Universal 2でビルドしたのですけど、Appleシリコン環境でzip圧縮したものを解凍するとアクセス権がおかしくなってしまう不具合がありました。
そこでUniversal 2をやめて、Intel版(x86_62)にビルドし直した「1.3.0 (48)」に差し替えました。AppleシリコンMacをお使いの方は再度ダウンロードしてくださいませ。