浮紙が用意している整形項目について説明します。
なお、ここでの「半角」は欧文のプロポーショナル幅の文字を指します。半角カタカナだけが半角幅の文字です。
結合文字列を合成する
結合文字列を合成するにあたって、互換漢字などが変化しないように安全にUnicode正規化形式のNFCを適用します。テキスト整形では必ず入れておくことを強く推奨します。
ストックパネルの「結合文字列を合成する」は、これと同等の処理をするPerlのサンプルです。
特定文字を確認する
環境設定[開く > 特定文字を確認]の設定に従って確認をします。あれば「特定文字を確認パネル」を表示して調べます。テキスト整形では一番最後に入れておくとよいでしょう。
注:v8.3.5で確認パネルを表示するだけにしました。
行頭
空白文字を削除
行頭に空白文字があればすべて削除します。
空白文字を全角1文字に統一
行頭に空白文字があれば、(空白文字が複数あっても)すべて全角スペース1文字に置換します。
行末
空白文字を削除
行末に空白文字があればすべて削除します。
カタカナ
すべて全角
半角カタカナをすべて全角カタカナに置換します。
全角カタカナを半角カタカナに置換する項目はあえて入れていません。
括弧
すべて全角
欧文の括弧をすべて全角括弧に置換します。対象は以下の6文字。
( ) [ ] { }
すべて半角
全角括弧をすべて欧文の括弧に置換します。対象は以下の6文字。
( ) [ ] { }
全角括弧の前後空白文字削除
全角括弧の前後に空白文字があれば削除します。ここだけ空白文字にはタブを含みません。
約物
縦組用約物を解決
Unicodeには縦組用の約物のコードポイントがあります。そもそも約物は縦組で自動的にグリフが変わるのであって、コードポイントが変わることはありません。縦組用の約物が混在していると、禁則対称にならなかったり、検索でヒットしなかったりするので、通常の約物に直します。対象は以下の33文字。
︐︑︒︓︔︕︖︗︘︙︰︱︲︳︴︵︶︷︸︹︺︻︼︽︾︿﹀﹁﹂﹃﹄﹇﹈
これらを以下に全置換します。
,、。:;!?〖〗…‥―‐_﹏(){}〔〕【】《》〈〉「」『』[]
アルファベット
すべて半角
全角アルファベットをすべて欧文アルファベットに置換します。
すべて全角
欧文アルファベットをすべて全角アルファベットに置換します。
X文字まで全角
サブメニューで1文字~6文字のいずれかを選択します。以下の条件で並んでいるアルファベットのうち、ここで選択した文字数まで並んでいるものを全角アルファベットにし、それ以外を欧文アルファベットにします。この項目より前の段階で英数字をすべて半角にしておくとよいでしょう。
- 行頭+アルファベット+行末
- 行頭+アルファベット+全角文字
- 全角文字+アルファベット+行末
- 全角文字+アルファベット+全角文字
数字
すべて半角
全角数字をすべて欧文数字に置換します。
すべて全角
欧文数字をすべて全角数字に置換します。
1桁のみ全角
以下の条件で並んでいる数字を全角数字にし、それ以外を欧文数字にします。この項目より前の段階で英数字をすべて半角にしておくとよいでしょう。
- 行頭+数字1文字+行末
- 行頭+数字1文字+全角文字
- 全角文字+数字1文字+行末
- 全角文字+数字1文字+全角文字
2桁のみ半角
以下の条件で並んでいる数字を欧文数字にし、それ以外を全角数字にします。この項目より前の段階で英数字をすべて半角にしておくとよいでしょう。
- 行頭+数字2文字+行末
- 行頭+数字2文字+全角文字
- 全角文字+数字2文字+行末
- 全角文字+数字2文字+全角文字
和欧間
欧文スペース削除
以下の条件で並んでいる1つ以上の欧文スペース(U+0020)を削除します。この項目より前の段階で英数字をすべて半角にしておくとよいでしょう。
- 全角文字以外+欧文スペース+全角文字
- 全角文字+欧文スペース+全角文字以外
漢字
CJK部首補助/康煕部首を解決
CJK部首補助/康煕部首を同一字形の通常の漢字に置換します(273文字)。Adobe-Japan1(2017-10-09)をベースにしています。AJ1では両者を同じグリフで表示するので、置換後の字形の違いはまったくありません。なお、この処理で置換されないものは、AJ1の通常の漢字に同一グリフが存在しない、またはAJ1に存在しないものであり、置換対象外です(58文字)。
互換漢字 → SVS漢字
UnicodeのStandardized Variantsに従って、互換漢字をSVS漢字に置換します。ここはoptionキーを押しながらダブルクリックをすると表示されます。
SVS漢字 → 互換漢字
UnicodeのStandardized Variantsに従って、SVS漢字を互換漢字に置換します。ここはoptionキーを押しながらダブルクリックをすると表示されます。
参考:SVS漢字の説明
互換漢字 → Adobe IVS
互換漢字をAJ1コレクションのIVSに置換します。ここはoptionキーを押しながらダブルクリックをすると表示されます。
Adobe IVS → 互換漢字
AJ1コレクションのIVSを互換漢字に置換します。ここはoptionキーを押しながらダブルクリックをすると表示されます。
重複行をまとめる
隣り合った行が同一なら一行にまとめます。
テキスト整形パネルメニュー:文字クラス設定…
上記の整形項目には、空白文字・約物・全角・半角といった区別が必要な処理が多く含まれています。こうした文字の区別を具体的にどのように設定しているのかは、テキスト整形パネルメニュー[文字クラス設定…]で確認できます。カスタマイズも可能です。
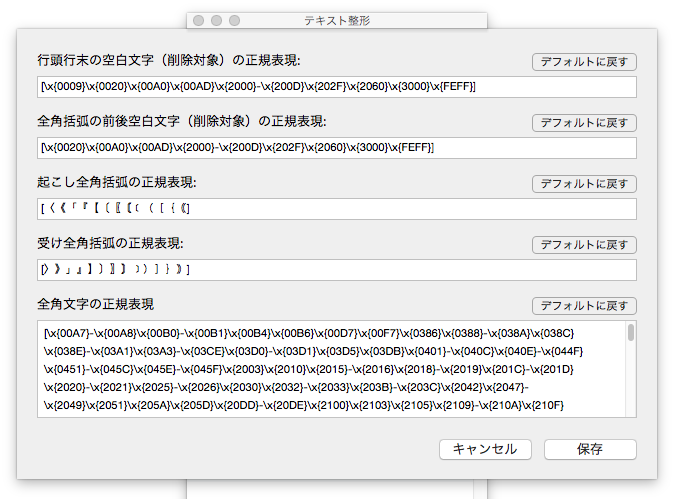
空白文字には2パターンを用いています。違いはタブがあるかどうかです。タブを含まない空白文字の文字クラスを使っているのは、項目「全角括弧の前後空白文字削除」だけです。
いわゆる全角/半角の区別は、Unicodeではかなり難題であって、唯一の解はありえません。浮紙ではDTP用のエディタとして、全角のコードポイントをAJ1を基準にある程度決めて、それ以外を半角としています。全角のコードポイントは下記のように決めました。
- Adobe-Japan1のUniJIS2004でデフォルトグリフが全角グリフのコードポイント。
- UniJIS2004でデフォルトグリフがプロポーショナルの4つの引用符「‘ ’ “ ”」を追加。
- Unicodeのすべての漢字のコードポイントを追加。
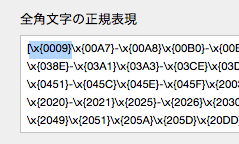
上記から重複を除いた浮紙採用の全角文字総数は95495個。これらを[全角文字の正規表現]として設定しています。
例:タブを全角文字扱いにする
文字クラス設定の[全角文字の正規表現]は、デフォルトでタブ(U+0009)を含んでいません。そのためタブ区切りテキストに「数字:1桁のみ全角」を実行しても、タブ直後の数字はすべて半角数字になります。タブ直後の1桁数字を全角数字に変換されるようにするには、[全角文字の正規表現]に \x{0009} を追加します。