
初版 2010/4/5
第2版 2013/5/10 誤解を修正。全面的に書き直し。
第3版 2014/7/13 なるべく分かりやすく全面的に書き直し。
第4版 2015/5/20 さらに分かりやすく全面的に書き直し。
第4.1版 2015/5/27 まだ分かりにくいと不評なので書き直し。
第4.2版 2015/5/27 さらに分かりやすく調整。
Unicode正規化の考え方自体はとてもシンプルです。でも、よく知ろうとしていろいろ調べると、用語がハイコンテキストすぎて、混乱してワケがわからなくなります。日本で一般的に見られる用語を図にしてみましょう。
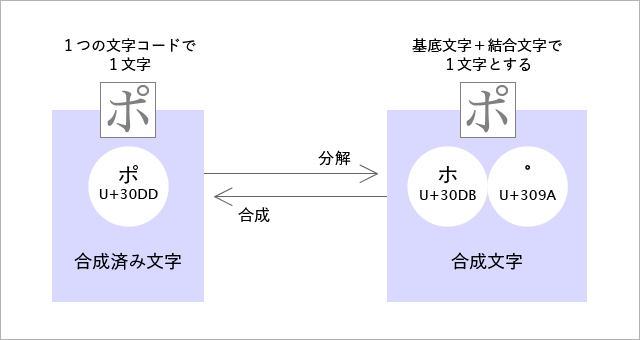
混乱するのはどこだと思いますか?
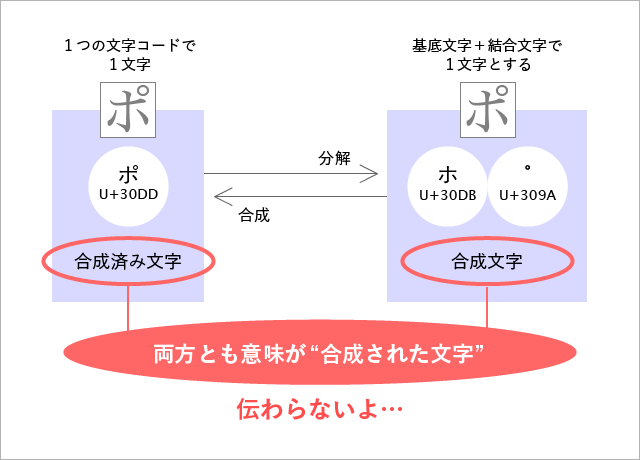
“合成済み文字” と “合成文字” の2か所です。どちらも言葉として同じ意味です。それなのに、異なった状態を表す用語として無理矢理に使い分けようとしています。ここから、以下のような奇妙な文章ができあがります。
- 合成された文字を分解すると合成された文字になる。
- 合成された文字を合成すると合成された文字になる。
ハイコンテキストというより、人に伝える言葉としておかしい。これで混乱するなというのは無理です。実は、権威筋の方々ほど、この混乱する用語の使い方をする傾向があるのです。
提案
この混乱を防ぐにはどうしたらいいのでしょうか。なんと、用語をたった1つ変えるだけで解決します。
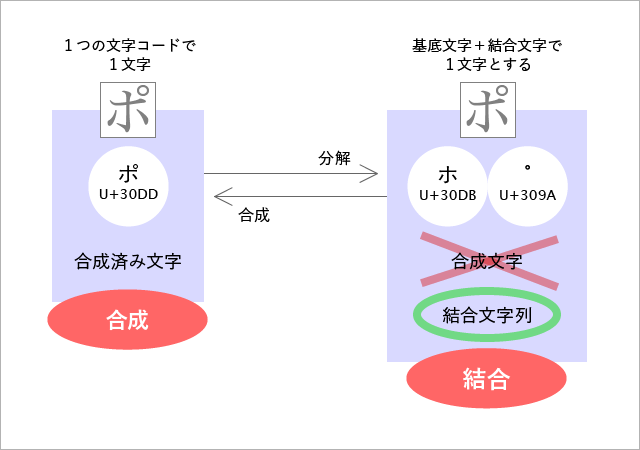
右側の “合成文字” を “結合文字列” にします。そうすると、右側の状態は “結合” となり、左右が異なった状態であることを用語ではっきり区別できるようになります。
この提案にはちゃんと裏付けがあります。
詳細
そもそも、冒頭の混乱はどうして起こったのでしょうか。答えを先に言うと、UnicodeとUCSの2つの規格で使われている用語を無理矢理に混在させているのが原因です。
UnicodeとUCS
UnicodeとUCSの関係を簡単に説明しておきます。Unicodeは私企業の団体が決めた標準規格、一方のUCS(ISO/IEC 10646)は公的な国際標準規格です。大人の事情でUCSはUnicodeをそのまま呑み込むことになり、文字コードの規格として両者はまったく同じものです。でも、両者の規格書の「解説文」は、それぞれが作成しているので同じではありません。とくに用語の相違が著しい。
用語の相違
まずUCSの用語から見てみましょう。
2014-09-01版PDFから採取。日本語訳はJIS X 0221から採取。
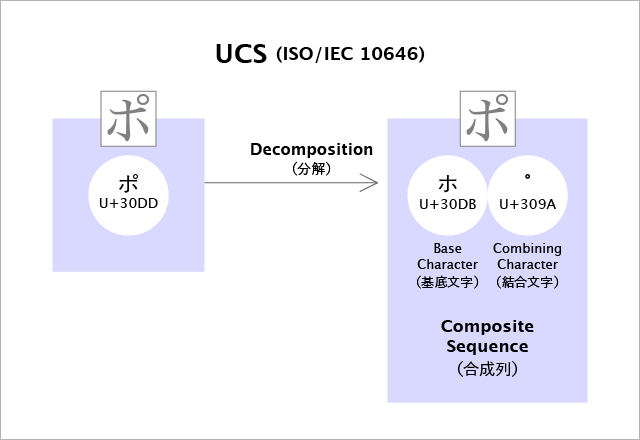
驚いたことに、UCSには左側の状態 “1つの文字コードで1文字” を表す用語が存在しません。あるのは “分解” だけで、その分解された結果を “Composite Sequence(合成列)” としています。
右側の “合成列” のアイデアは、UCSが発祥です。権威筋の方々がこれを “合成” と呼ぶのはそこに由来するようです。ちなみに、これを “合成文字” と呼ぶのはUCSの規格書でも使われていないスラングです。
Unicode正規化は、左右の状態を対として扱っています。しかし、UCSの用語にあるのは右側だけ。つまり、USCの用語では、どうやってもUnicode正規化を記述できないのです。そのため、規格書の『21 Normalization forms』では「Normalization forms … are specified in the Unicode Standard UAX#15」とUnicodeへ丸投げし、自ら解説することを放棄しています。
それでは、Unicodeの用語はどうでしょうか。
UAX#15のrev.41から採取。日本語訳は英日用語集から採取(ただし「結合文字の並び」は採用せず「結合文字列」を採用。理由は記事下のコメントで説明)。
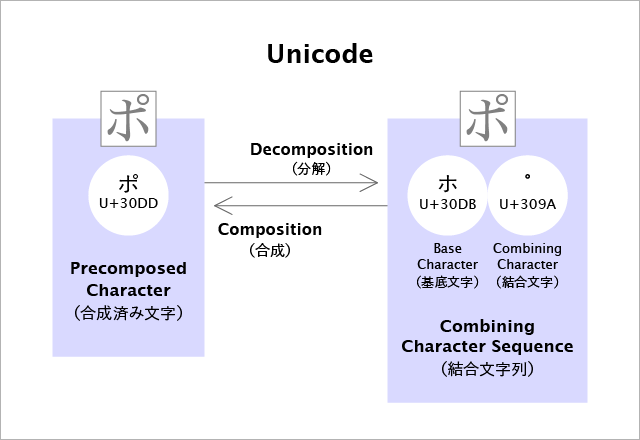
左右の状態を対として扱い、用語でも状態を区別できるようにしっかりと配慮されています。
冒頭の用語の混乱は、UCSの用語で表せないところをUnicodeの用語で補っているのが原因です。混乱して当たり前ですよね。
この混乱を防ぐには、以下の3点が必要です。
- Unicodeの用語体系を採用し、さらにその体系を前提にしていることを自明とする
- UCSの用語体系を使うときは「UCSの合成」と明示する
- 「合成文字」という用語を使わない
上記の提案で「用語をたった1つ変えるだけで解決する」としたのは、Unicodeの用語体系を採用することなのです。
Tweet
Unicodeの英日対訳で「Combining Character Sequence」を「結合文字の並び」にしているのは誤訳だと思います。
Combining Character Sequenceは「基底文字と結合文字の並び」であり、文字列が結合した状態を指しています。「結合文字の並び」にしてしまうと、結合文字だけが並んでいる状態を指すことになってしまい、どう見ても誤りです。
日本語訳は「結合文字列」にするのが(曖昧さは残りますが)落とし所でしょう。