
DTP制作向けのテキスト整形の話です(楽しい文字沼)。
CJK部首補助や康煕部首の漢字は、とてもやっかいです。なにがやっかいかというと、見た目では通常の漢字と区別ができないことです。

文字コードが違うのにどうして見た目がこれほど同じなのかというと、フォントの同じグリフが表示されているからです。

クライアントから支給された文字原稿に、もしかするとこのやっかいな漢字が混入しているかもしれません。なぜかというと、PDFから文字をコピーすると、通常の漢字だったはずなのに、なぜかやっかいな漢字に変わってしまうことがあるからです。このごろは文字原稿の作成にPDFから文字をコピー&ペーストすることが普通に行われているので、やっかいな漢字の混入は日常茶飯事といってよいかもしれません。
クライアントからPDFを支給されたときも、DTP制作者がPDFから文字をコピー&ペーストして、気づかずにやっかいな漢字を混入してしまうかもしれません。
やっかいな漢字は、通常の漢字と文字コードが違うので、DTP用アプリでは検索でヒットしません。通常の漢字「見」を検索しても、康煕部首の漢字「⾒」にはDTPアプリでヒットしないのです。そのせいで事故になってしまうおそれがあります。
どうすればいいのか
文字原稿に混入したやっかいな漢字を解決するにはどうすればいいのか。それは、単純に通常の漢字へ置換するしか方法はありません。そこで検索置換用の一覧を作ってみました。
CJK部首補助または康煕部首を解決する一覧.txt
よかったら参考にしてみてください。
ちなみに、浮紙にはデフォルトで「CJK部首補助/康煕部首を解決」の機能があるので、浮紙愛用家の皆さんは必ずこれを仕込んでおくのを推奨します。
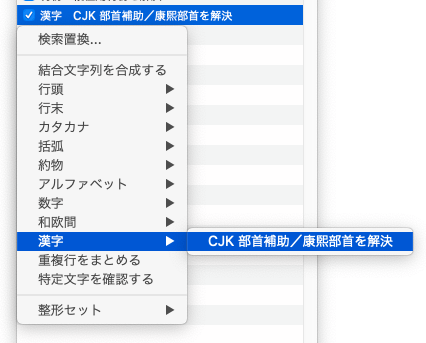
なお、Unicodeのプロパティには、やっかいな漢字を通常の漢字にマッピングした EquivalentUnifiedIdeograph があります。これは「⺌」「⺍」を「小」にマッピングしていたりするので、見た目を変えたくないDTPでは使いにくいかもしれません。場合によってはこちらの方が有効かもしれないので、こういう資料もあることは知っておいた方がよいでしょう。
Tweet