
源ノ明朝/角ゴシック-1 の続きです。
前回は、ダウンロードしたフォルダを下図のように整理しました。
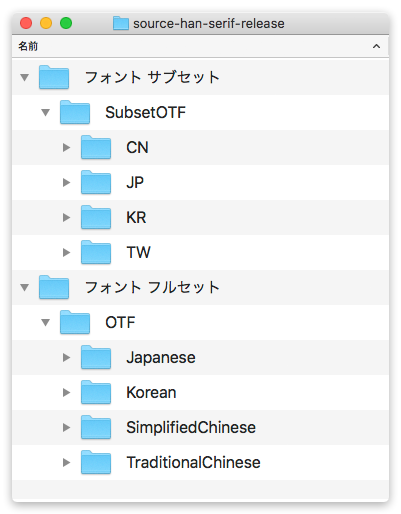
これをさらに分かりやすくしましょう。フォルダ名を下図のようにしてみてください。
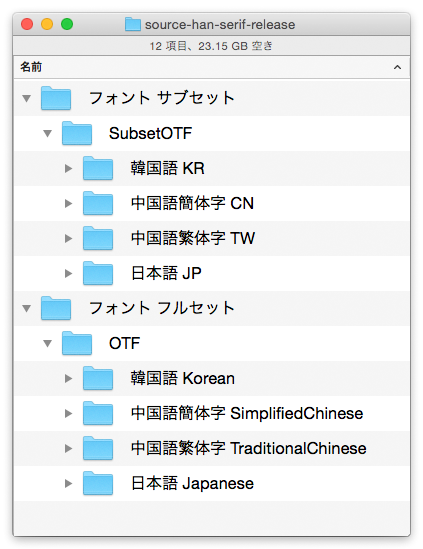
「サブセット」「フルセット」の中に、それぞれ同じ4つの言語があることが分かります。
注:簡体字/繁体字は言語の違いではありませんが、表現を簡略にするため、ここではあえて言語と表記します。
サブセット? フルセット?
そもそも、「サブセット」「フルセット」は、どういう意味なのでしょうか。
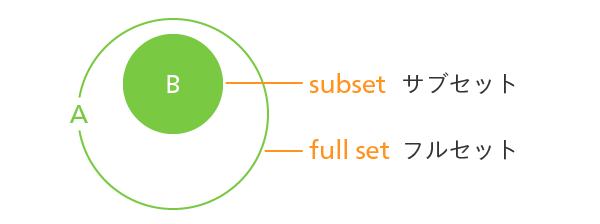
上図は、Aの中にBが含まれている様子です。Bは部分集合で、英語でsubset(サブセット)といいます。Aは、ITの世界ではfull set(フルセット)と呼ばれます。
つまり、機能をすべてフルに搭載した状態がフルセット、その機能を部分的に搭載した状態がサブセットです。
源ノ明朝/角ゴシックには、「すべての文字をフルに搭載したフルセット版」と「各言語に必要な文字を選別して搭載したサブセット版」の2種類があるのです。
文字数の違い
サブセットとフルセットの違いは、使える文字の数にあります。どのくらい違うのでしょうか。ここで大まかに源ノ明朝を見てみましょう。
文字っ子向け:この項目で比較する文字数は、グリフ数ではなく、CMapのコードポイント数です。
フルセットの文字数は4つの言語いずれも完全に同じです。一方、サブセットの文字数は、言語ごとに下図のように異なります。
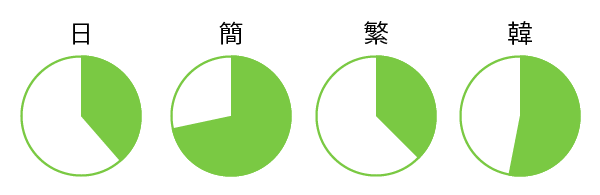
これをさらに漢字/非漢字に分類してみましょう。
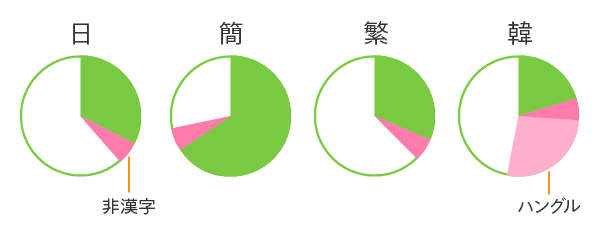
非漢字の文字数は、実は4つとも完全に同じです。そこには日本語の仮名なども共通して含まれています(韓国語だけは非漢字にハングルがあります)。サブセットの4つの言語の最も大きな違いは、漢字の文字数なんですね。
サブセット版の漢字は、各言語に合わせて選別されています。そして、各言語で使わない漢字は使えません。使えない漢字は、豆腐に化けたり、自動的に他のフォントで表示されたりします。そうした欠点はあるものの、シンプルな分かりやすさがあるので、一概に良い悪いといえるものではありません。
次回は、フルセット版の説明をします。サブセットのシンプルさとはうってかわって、フルセットにはとても分かりにくいところがあります。しかし、この分かりにくさは、源ノ明朝/角ゴシックのせいではありません。すべての原因は「Unicodeの漢字統合」にあります。この問題に対処するため、時代を先取りした先鋭的なフォント技術を駆使しているのが源ノ明朝/角ゴシックのフルセット版なのです。次回が本当の最難関。うまく説明できるといいなぁ…。
Tweet