
源ノ明朝/角ゴシック-3の続きです。
ここでは源ノ明朝/角ゴシックを使うときに知っておきたい「Unicodeの漢字統合」を説明します。そもそも、どうしてここでUnicodeが出てくるのでしょうか。
どこもかしこもUnicode
Unicodeは、世界中の文字を同時に一緒に使うためのものです。இとか☯︎とか∭とか、さらに😀のような文字がここで日本語と一緒に表示できるのは、ここにいるのがUnicodeの文字コードだからです。
パソコンやスマホにデジタルの文字が表示されていたら、そこにいるのは例外なくUnicodeの文字コードだと思ってかまいません。そのくらい今は満遍なく広く行き渡っています。源ノ明朝/角ゴシックもUnicodeがネイティブな文字コードです。
Unicodeの漢字
それぞれの文字コードが「何の文字なのか」は、1文字ずつ人間が考えて決めています。
例えば、“あ” は日本語の平仮名のひとつ。他のいろいろな文字から区別するのに、とくに悩むことはありません。
ところが、世界中の漢字を同時に一緒に扱おうとすると、悩ましいことになります。漢字は国や地域によって、同じだったり違っていたりするからです。
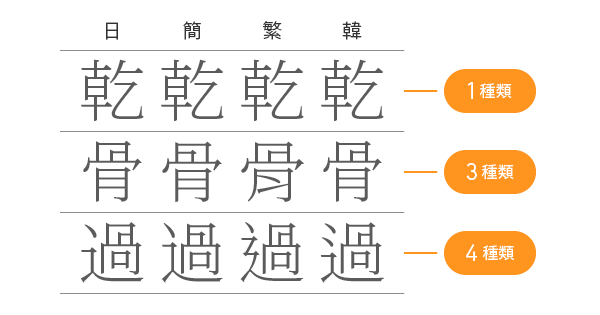
長い年月の間にそれぞれに変わってきたんですね。こうした状態なので、私たちは文字コードでもそれぞれ別々にすればいいじゃない、と普通に考えます。しかしUnicodeの中の人たちは、それを良しとしませんでした。漢字の数があまりに膨大すぎて、Unicode全体が肥大化しすぎてしまうからです。
そこで採用されたのが「漢字統合」という節約アイデア。そもそも文字コードは、Unicodeに限らず、同じ文字なら文字コードは1つだけにします。Unicodeはそれを漢字でさらに推し進め、国や地域が違っても、漢字は統合して文字コードは1つだけとしたのです。
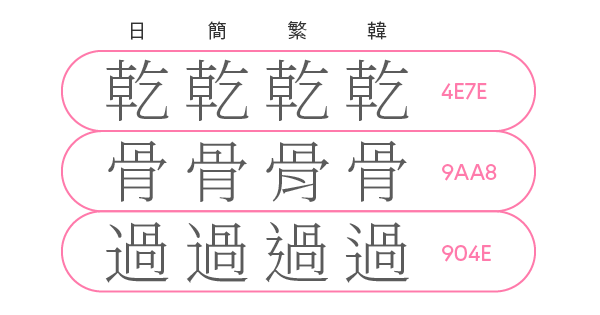
つまり、漢字の文字コードには、それがどの国や地域の漢字なのか、その区別がありません。使い分けるには文字コードではなく、ユーザーがフォントで決める。これが漢字統合の方針です。
ここで前回の「文字コードがペアになれるフォントのグリフは1つだけ」を思い返してください。それぞれの漢字を区別するには、それぞれの専用フォントをユーザー自身が使い分ける必要があるのです。
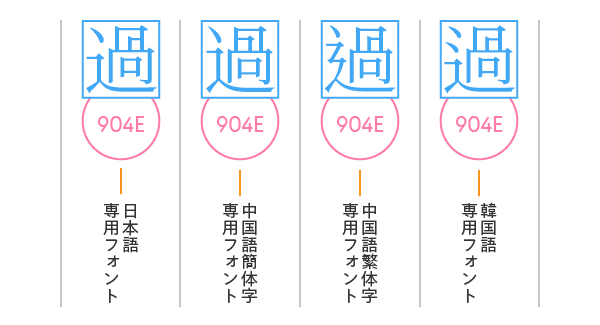
すべて統合されているわけでない
それでは、専用フォントにすれば、自動的にそれぞれの漢字になるのでしょうか。実は、全ての漢字がそうなるわけではありません。ここが大変に重要なところです。

例えば、漢字「桜」はそれぞれ上図の違いがあるのですが、文字コードは別々になっています。使い分けはフォントだけでなく、文字入力でもしなければいけません。
漢字によって文字コードが同じだったり別々だったりするので、なにかそこに方針があるのかと思いきや、あるようでないような、よく分からないことになっています。
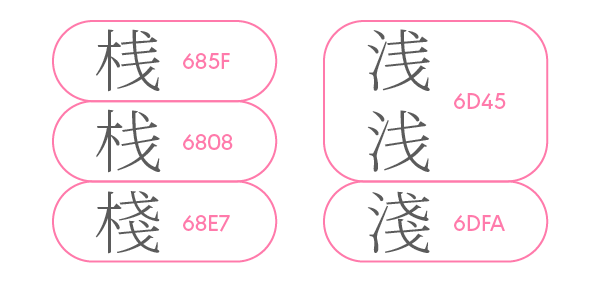
結構グダグダなんですね。
このあたりをもっとしっかり知りたい方は、専門家の先生が分かりやすく説明している「日本の文字とUnicode 第4回 | 大修館書店 WEB国語教室(Internet Archive)」がオススメです。
次回は、源ノ明朝/角ゴシックのフルセット版の特徴を説明しますね。
Tweet