InDesignドキュメント(.indd)を作成バージョンより新しいバージョンで開くと、文字化けしたり、文字組みが変化したりする可能性が大いにあります。これは、InDesignがバージョンアップ時に不具合を修正したり、仕様を変えたりするのが原因です。しかもリリースノートに記載されない場合もあり、そのようなものは一部の人たちだけが発見して知っているような状況です。もちろん、それまでなかったバグが新たに発生している場合もあります。
こうした情報をまとめたものが見当たらなかったので、ここにまとめておくことにしました。漏れがありましたら教えてくださいな。
なお、新しいバージョンで開いたときの変化を人の目だけで見つけ出すのは100%不可能です。「inddを新しいバージョンで開くと必ずどこかが変化する」と考え、PDFで差分を比較するなどして、しっかり確認をしないと簡単に事故になってしまいます。
このページを作ったのは、InDesignドキュメントを新しいバージョンで開くなんていうのは不用意に気軽にしていいことではないと注意喚起するのが目的です。
全バージョン
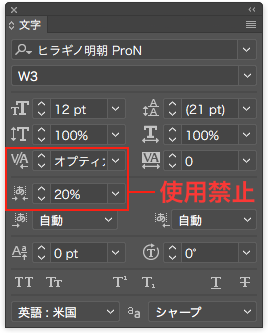
InDesignで引用符を合成フォントの特例文字で欧文フォントにしている場合の引用符のアキ量設定の文字クラス
CS3 以降
矢印系の文字が欧文扱いされたので、欧文の行分割禁止の影響を受けるようになった。
InD-Board No.7794
CS4 以降
[角オプション]の角丸の円弧形状は当初から少し歪んでいたが、CS4で四角個別に設定可能になったのに合わせてさらに歪みが悪化した。
CS5 以降
「欧文泣き別れ」の仕様が変更された。
InDesign CS5の「欧文泣き別れ」はハイフネーションと連動している – 実験る~む
CS5 以降
字形パネルの言語が「言語なし」になっている文字でグリフ置換が無効になった。
https://twitter.com/monokano/status/1068759462507274240
CS5 以降
不正な異体字属性が適用された文字が化ける。
InDesignの異体字属性伝染と文字化け(深刻なバグ) – ものかの
CS5 以降
同一行にBMP外の文字が存在するとカスタムのアンカー付きオブジェクトの直前に意図しないアキが発生する。
(CS5以降)アンカー付きオブジェクトの前にアキができる |Adobe Community
CS5 以降
特定の条件でルビが文字化けする(□に╳のミッシンググリフになる)。
フォントはファミリー単位で運用するのが吉 – 実験る~む
CS6 以降
SINGが全廃され、SINGを利用して表示していた文字が化ける。
【InDesign CS6】SINGを使ったドキュメントを開いてみる
CS6 以降
約物に設定した圏点が表示されない。
Indesign CS6における圏点の仕様について – DTP駆け込み寺
CS6 以降
文字に適用した効果がPDF/X-4で書き出すと消失してしまう。
InDesignで内側に掛かるオブジェクト効果を使ってPDF/X-4保存すると効果が消える
※CC 2018で修正された。
CS6 以降
連数字処理の仕様が変わった(不具合?)。
InDesignではCS6から単数行コンポーザーの結果が変わる
CS6(8.1)以降
「ここまでインデント」の不具合が修正された。ただし、CC 2014のみ不完全なまま。
No.03 ここまでインデントの不具合修正 | InDesign CC 2014 | InDesignの勉強部屋(2014.6.19)
InDesign CS6 8.1.0 リリースノート(2015.1.29)
CC (9.3) 以降
合成フォントの数字がアキ量設定で欧文の文字クラスにされる不具合が修正された。
合成フォントを使用すると和欧間の文字組み設定が正常に動作しない (InDesign CC)
CC 2014.2 以降
.otfの欧文フォントの日本語の文字がアキ量設定で欧文扱いされる不具合が修正された。
CC 2019(14.0)
正規表現エンジンがUnicode 5.1準拠からUnicode 9.0準拠に変更され、略記法でマッチする文字が増えた(注:マッチ対象から外れた文字もある)。
正規表現の略記法 \d と \s と \w
CC 2019(14.0)
CS5以降の「同一行にBMP外の文字が存在するとカスタムのアンカー付きオブジェクトの直前に意図しないアキが発生する」不具合が直った。
2020(15.0)
CS4で悪化していた[角オプション]の角丸の歪みが修正された。
Adobe InDesign Feedback – Rounded corners aren’t perfectly rounded
2020(15.0)
縦中横に下線が表示されない不具合が修正された。
When applying underline feature to TateChuYoko, the underline doesn’t show
2020(15)
正規表現エンジンがUnicode 12.0準拠に変更され、略記法でマッチする文字が増えた。
2021(16)
正規表現エンジンがUnicode 13.0準拠に変更され、略記法でマッチする文字が増えた。
「互換性への配慮がありません」
PDF & 出力の手引き 2020 – Adobe Blogs
こちらからダウンロードできる「InDesign互換性ガイドブック」のPDFには、そもそも互換性を配慮していないことが明記されています。なお、ここまでちゃんと言い切ったのはAdobe Japanの良心であると私は評価しています。
その他
特にCS6以降、マスタースプレッド内のグループオブジェクトを、ローカルページ上でオーバーライドして移動など含む編集をした場合、PDF書き出し時に(ランダムですが)オーバーライド前のマスターオブジェクトまで書き出されるバグあるんでお気をつけください。言葉で説明すんのムズイすけどw
— Yusuke S. (@Uske_S) May 18, 2017