
「普通のUnicodeはNFC」というおかしな風説が流布されています。文字っ子にしてみれば「なに言ってんの?」となるのですが、この風説のどこがおかしいのかを説明しようとすると途方に暮れます。もうどこから突っ込んでいいのか分からない。
一番難しいのは「普通のUnicode」自体が何を指しているのか分からないことです。Unicodeに「普通」とか「普通じゃない」なんて区別はありません。でも区別してそう言っている。どこで区別しているんだろう?
zrbabblerさんがブログ記事「“普通のユニコード”は NFC なのか」を公開されました。ここでは「普通のUnicode」を「レガシーエンコーディングから変換して得られたUnicode文字列」としています。実証的な説明をするにあたってこれしかないというくらいに秀逸ですし、説得力があります。
ただ、「普通のUnicode」と言っている人たちは、そういう意味で言っているのではないような気がするんですね。そこでzrbabblerさんのブログ記事とは別の視点で考えてみることにしました。
何が普通なのか
「普通のUnicode」のコンテキストは、Unicodeの合成と分解にあります。
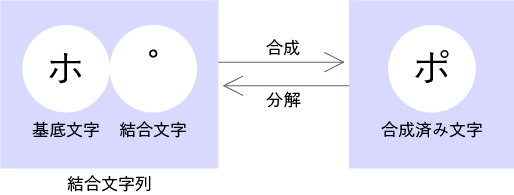
カタカナ「ポ」は、結合文字列「U+30DBとU+309A」、合成済み文字「U+30DD」のどちらでも表現できます。そして私たちが文字を入力したり編集したりするときは、特段に意識することなく合成済み文字「U+30DD」を使います。半濁点を分離しようなんて考えません。
このように、合成済み文字と結合文字列の2種類があるとき、合成済み文字を選択するのは普通の感覚です。つまり「普通のUnicode」とは、普通の文字感覚に合致しているUnicode文字列を指すのではないではないかと思われます。
この普通の文字感覚は、「1文字が1つの符号位置」を当たり前と感じ、それを自然に感じる志向です。この志向を表す用語がどこにもないので、ここでは仮に「単一符号位置志向」と名付けてみます。
単一符号位置志向とNFCはまったくの別物
私たちはUnicode文字列をたしかに単一符号位置志向で扱います。しかしこれを「普通のUnicodeはNFC」と言ってはいけません。
Unicode正規化は、ソフトウェアがバックグラウンドで文字列照合をするときに使われるものです。文字列照合とは、ある文字とある文字が同じなのか、違うのか、違う文字ならどちらを先に並べるのかを判定することです。このときにカタカナ「ポ」のような異なる符号位置で表現できる文字が問題になります。U+30DBとU+309Aの「ポ」とU+30DDの「ポ」は同じ文字と判定されなければいけません。しかしソフトウェアは符号位置で照合をするので、違う文字と判定してしまいます。そこで判定前に「同じ文字なら同じ符号位置に揃える」という変換処理が必要になります。この変換処理がUnicode正規化です。ここで変換された文字列は照合が済めば人間の目に触れることなく消されます。
Unicode正規化形式のNFCは、結合文字列を合成して単一符号位置に揃えます。これに加えて、互換漢字を統合漢字に変えるような処理も行われます。「同じ文字なら同じ符号位置に揃える」からです。

互換漢字「羽」と統合漢字「羽」は、文字列照合で同じ文字と判定されなければいけません。そのためUnicode正規化形式のすべてでこの処理が行われ、統合漢字に揃えられます。
私たちの普通の文字感覚では、互換漢字を統合漢字に変えるなんて、よほどの意図がない限りしません。一律に勝手にそんなことをしてはいけないとさえ感じます。NFCは、Unicode文字列を普通の文字感覚に合わせることが目的ではないのです。
普通の文字感覚としての単一符号位置志向と、文字列照合の前処理としてのNFCは、似て否なるまったくの別物です。これを混同してはいけません。
ところが実際に本当に混同してしまい、ユーザーに何の警告なく勝手にNFCを適用してしまうトンデモない実装が蔓延しています。このトンデモ実装をくれぐれも真似しないようにしてください。
Tweet
「普通のUnicodeはNFC」と同様の風説に「WindowsはNFC」があります。
このようなことを言ってしまう人は、もしかするとUnicode正規化形式をエンコーディング変換形式だと思い込んでいるのかもしれません。
Unicode正規化はエンコーディング変換ではないですし、Unicode正規化形式はエンコーディング変換形式ではありません。この誤解はかなり根深く蔓延している気がします。